Building on Part 1’s architectural foundation, this technical guide addresses the practical implementation of IBM i disaster recovery testing and operational management. We examine the specific procedures for testing IBM i DR environments, managing journal receivers, handling role swaps, and optimizing ongoing operations.
The unique characteristics of IBM i—from its work management subsystems to its integrated security model—require specialized testing procedures and disaster recovery best practices that differ significantly from distributed systems. This guide provides actionable frameworks for implementing and maintaining enterprise-grade managed disaster recovery for IBM i environments.
Implementation Reality Check
While specific industry-wide IBM i DR failure rates lack current substantiation, organizations that implement comprehensive disaster recovery testing services significantly reduce failover problems and achieve faster recovery times than those using generic DR procedures. According to Fortra’s 2025 survey, only 10-15% of IBM i shops have deployed comprehensive HA/DR solutions despite 62% ranking it as a top priority—highlighting a significant implementation gap.
The total cost of ownership for properly managed it disaster recovery solutions shows interesting patterns: while initial implementation costs may be higher due to specialized expertise requirements, operational costs over time often prove lower due to reduced failed tests, fewer emergency consultations, and more efficient resource utilization.
Section 4: IBM i DR Testing Deep Dive
4.1 IBM i-Specific Testing Methodologies
Implementing effective disaster recovery testing for IBM i requires understanding of unique system characteristics:
Save/Restore Testing vs. Replication Testing
IBM i offers two fundamental testing approaches that disaster recovery vendors must support:
Save/Restore Testing:
- Full System Save
- LPAR Restoration
- Library Recovery
- Application Verification
Replication Testing:
- Journal Apply Verification
- Object Synchronization Check
- Authority Validation
- Role Swap Simulation
Subsystem Testing Procedures
IBM i subsystems require specific startup sequences during recovery—a critical aspect of disaster recovery best practices:
- QCTL (Controlling Subsystem): Must start first when configured as controlling
- QINTER (Interactive): User access subsystem
- QBATCH (Batch): Batch job processing
- QSPL (Spooling): Print management
- Custom Subsystems: Application-specific order
Test Script Framework for Subsystem Validation
/* Verify Subsystem Status After Role Swap */
PGM
DCL VAR(&QCTLSTS) TYPE(*CHAR) LEN(10)
DCL VAR(&QINTERSTS) TYPE(*CHAR) LEN(10)
/* Check controlling subsystem if applicable */
RTVSYSVAL SYSVAL(QCTLSBSD) RTNVAR(&QCTLSTS)
/* Validate status and alert if issues */
/* Continue checking other subsystems... */
ENDPGM
4.2 Journal Management During Testing and Operations
Journal receiver management is critical for managed disaster recovery success:
Journal Receiver Chain Management
Maintaining journal continuity during replication requires careful handling—a key differentiator among disaster recovery companies:
- Dual Attachment: Consider keeping receivers attached on both systems during testing
- Threshold Management: Set appropriate thresholds based on change volume
- Chain Break Prevention: Never delete receivers until confirmed applied
- Recovery Point Markers: Use journal markers for consistent recovery points
Journal Receiver Sizing Considerations
Sizing factors for disaster recovery planning:
- Peak transaction volumes
- Batch processing windows
- Available storage capacity
- Network replication bandwidth
- Recovery point objectives
Journal Performance Optimization Techniques
Optimize Journal Entry Size:
- Journal only required images based on recovery needs
- Use MINENTDTA options appropriately
- Consider field-level journaling where applicable
Configure Bundle Settings:
- Adjust bundle size based on network characteristics
- Monitor bundle wait times
- Balance latency vs. efficiency
Consider Parallel Processing:
- Configure multiple apply jobs where beneficial
- Monitor for lock conflicts
- Balance by application or library
4.3 Role Swap Procedures for IBM i
Role swapping IBM i systems requires precise coordination—a critical component of disaster recovery testing services:
Pre-Swap Validation Checklist
- Journal lag within acceptable range
- Object groups synchronized per requirements
- Active batch jobs properly managed
- Users notified per communication plan
- Network routing prepared for change
- Application end-points ready to redirect
Controlled Switchover Process Framework
This framework represents disaster recovery best practices for IBM i environments:
Quiesce Production:
ENDSBS SBS(*ALL) OPTION(*CNTRLD) DELAY(nnn)Final Synchronization:
- Ensure journals caught up
- Verify with monitoring tools
End Replication:
- Stop apply processes per vendor procedures
- Record final synchronization points
Network Cutover:
- Update DNS/routing as planned
- Clear caches as needed
Start Target System:
- Follow established startup procedures
- Verify all services active
Timing varies based on environment complexity
Post-Swap Verification
Critical validation points that disaster recovery vendors should include in their procedures:
- Job queue processing status
- Output queue accessibility
- User profile authentication
- Application functionality
- Database trigger activation
- Scheduled job resumption
4.4 Testing Automation Considerations for IBM i DR
Automation can reduce human error and improve testing frequency in managed disaster recovery implementations:
Automation Framework Components
IBM i DR Test Automation for IT Disaster Recovery Solutions:
- Native CL Programs
- System monitoring
- Status checking
- Basic validation
- SQL Procedures (QSYS2.DISPLAY_JOURNAL)
- Data verification
- Integrity checks
- Comparison queries
- Modern Scripting
- API testing
- Service validation
- Report generation
- Orchestration Tools
- Test coordination
- Network automation
- Startup sequences
Note: IBM does not provide specific CL programming templates for DR automation. Organizations must develop custom solutions or leverage disaster recovery companies with proven automation frameworks.
Journal Lag Monitoring Using SQL
-- Example monitoring approach for disaster recovery testing
-- Specific implementation depends on journaling configuration
CREATE PROCEDURE MONITOR_JOURNAL_STATUS()
LANGUAGE SQL
BEGIN
-- Use QSYS2.DISPLAY_JOURNAL with appropriate parameters
-- Implementation varies by environment
END;Section 5: Operational Excellence for IBM i DR
5.1 Day-to-Day DR Operations Management
Managing IBM i backup disaster recovery requires consistent operational discipline:
Daily Operational Tasks
These tasks form the foundation of disaster recovery best practices:
Regular Checks:
- Review replication status reports
- Verify all replication jobs active
- Check logs for anomalies
- Validate synchronization status
Periodic Tasks:
- Analyze receiver usage patterns
- Review performance metrics
- Update documentation for changes
- Conduct component testing
Scheduled Reviews:
- Full disaster recovery testing per policy
- PTF level comparison
- Capacity planning review
- Security synchronization audit
5.2 Performance Optimization Strategies
Optimizing it disaster recovery solutions performance requires system-level understanding:
Memory Pool Considerations for Replication
Example Pool Allocation for Disaster Recovery Planning:
- *MACHINE: Minimum required (typically 10-15%)
- *BASE: System operations (20-30%)
- *INTERACT: User access (as needed)
- *SPOOL: Print services (minimal)
- Custom: Replication processes (sized appropriately)
- Custom: Application pools (as required)
Storage Performance Considerations
These factors are crucial when selecting disaster recovery vendors:
- Journal Receivers: Place on appropriate performance tier
- Work Areas: Consider separate storage for temporary objects
- IASP Configuration: Independent ASPs for switchover efficiency
- RAID Configuration: Balance performance and protection
Network Optimization Techniques
TCP/IP Tuning (CHGTCPA):
- Set buffer sizes based on network characteristics
- Consider values like 524288 for WAN replication
- Test and adjust based on performance
Network Configuration:
- Verify line speed settings
- Configure duplex appropriately
- Consider dedicated replication networks
Frame Size Optimization:
- Jumbo frames for local networks where supported
- Standard frames for WAN based on path MTU
5.3 Advanced DR Scenarios for IBM i
Complex environments require sophisticated disaster recovery planning strategies:
Multi-System DR Coordination
When multiple IBM i systems must fail over together in managed disaster recovery scenarios:
Coordinated Failover Considerations:
- Dependency Mapping
- Identify system interdependencies
- Sequencing Requirements
- Determine proper startup order
- Synchronization Points
- Establish coordination checkpoints
- Network Coordination
- Plan unified cutover
- Validation Procedures
- Verify complete ecosystem
Handling Mixed Workloads During DR
Production and development on same DR system—a consideration for disaster recovery companies:
- Use work management for resource control
- Implement job priority schemes
- Set subsystem resource limits
- Consider commitment control for isolation
Cross-Platform DR Integration
IBM i + distributed systems recovery in it disaster recovery solutions:
- Time synchronization critical (NTP)
- Coordinate recovery points
- Match timestamps across platforms
- Test integration points post-failover
Section 6: ROI and Business Case for IBM i DR
6.1 Quantifying IBM i DR Investment Returns
The business case for managed disaster recovery extends beyond simple downtime prevention:
Operational Efficiency Gains
Organizations with mature IBM i DR report measurable improvements through disaster recovery testing services:
- Development Enablement: DR infrastructure used for development/testing provides additional capacity valued by reduced infrastructure needs
- Change Risk Mitigation: Ability to test PTFs and OS upgrades on DR systems reduces failed changes
- Compliance Confidence: Documented disaster recovery testing satisfies audit requirements, reducing preparation effort
Cost Avoidance Calculations
Beyond traditional downtime costs, IBM i environments face unique financial risks:
- Recovery Time Impact: Extended recovery times compound productivity losses
- Expertise Costs: According to the 60% of organizations reporting IBM i skills shortage (Fortra 2025), emergency consulting commands premium rates
- License Compliance: Proper DR licensing prevents audit penalties
6.2 Building the Executive Business Case
Presenting investment in disaster recovery vendors to leadership requires platform-specific arguments:
Strategic Value Points
- Business Continuity: IBM i typically runs mission-critical applications where downtime directly impacts revenue—particularly important for disaster recovery for financial services
- Regulatory Compliance: Industry requirements mandate demonstrable recovery capabilities through disaster recovery testing services
- Modernization Foundation: DR infrastructure provides safe environment for transformation initiatives
- Operational Resilience: 96% ROI satisfaction reported by IBM i shops (Fortra)
Investment Considerations
Organizations should evaluate when selecting disaster recovery companies:
- Initial implementation costs vs. long-term operational savings
- Risk mitigation value based on actual downtime costs
- Compliance requirement satisfaction
- Strategic enablement opportunities
Section 7: Future-Proofing IBM i DR
7.1 IBM i Modernization and DR Evolution
As IBM i systems evolve, disaster recovery planning strategies must adapt:
Modern Integration Patterns
While IBM i itself maintains its integrated architecture:
- Open source integration increasing (Node.js, Python)
- API-first architectures emerging
- Cloud service integration expanding
- Modern DevOps practices adoption
Current Technology Adoption
According to recent surveys relevant to disaster recovery vendors:
- IBM i 7.5 usage jumped from 19% to 32% as primary OS
- POWER10 adoption exceeded 50%
- 20% of organizations planning to increase IBM i footprint
7.2 Cloud-Native IBM i DR
The evolution toward cloud-based it disaster recovery solutions:
IBM Power Virtual Server Considerations
- 650+ customers across 21 datacenters globally
- Integrated backup disaster recovery packages available
- Network latency and bandwidth planning critical
- Storage tier selection for journal performance
Hybrid Architecture Patterns
Common Hybrid Approaches for Managed Disaster Recovery:
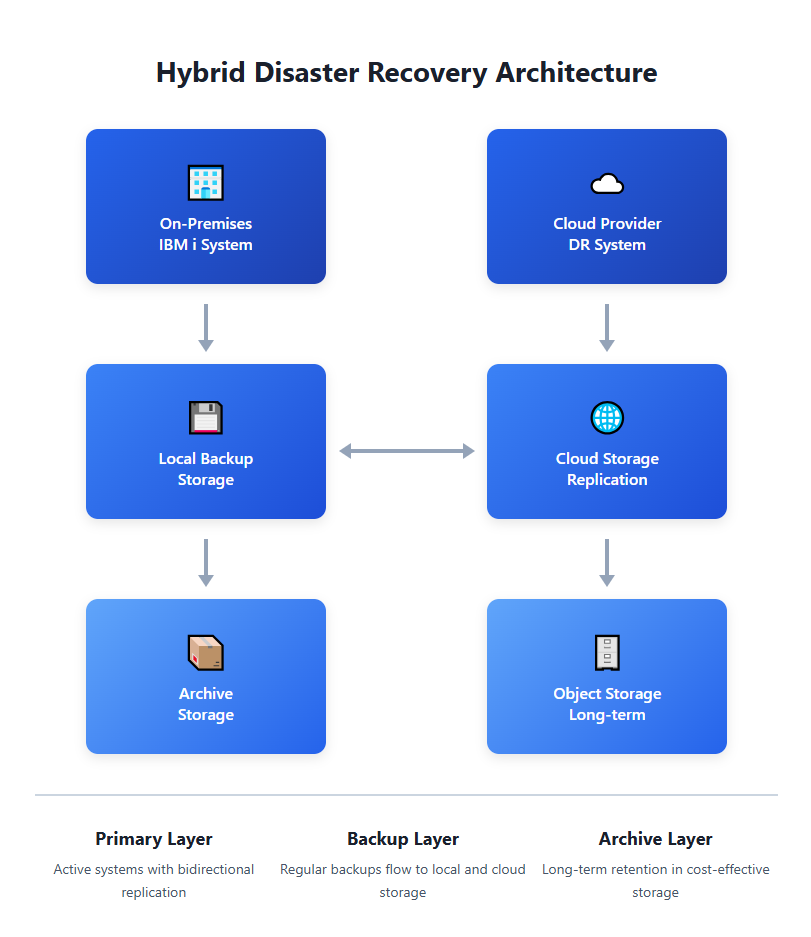
Latest Storage Technology
Important considerations when evaluating disaster recovery companies:
- IBM FlashSystem: Replaced Storwize brand (February 2020)
- DS8A10/DS8A50: Latest generation (October 2024) with up to 2 PiB capacity
- Enhanced cyber resilience features
- Improved replication capabilities
Conclusion
IBM i disaster recovery best practices require deep platform knowledge, specialized tools, and operational discipline that generic DR solutions cannot provide. The unique architecture of IBM i—particularly its single-level storage which simplifies many DR aspects—demands purpose-built approaches to replication, testing, and recovery.
Successful IBM i DR implementations focus on platform-specific requirements: managing journal receivers efficiently, understanding subsystem dependencies, coordinating LPAR resources, and maintaining object relationships during replication. Organizations that invest in IBM i-optimized managed disaster recovery solutions and procedures achieve faster recovery times, lower operational costs, and higher confidence in their business continuity capabilities.
The key to IBM i DR success lies in understanding and leveraging its unique characteristics to build a resilient, efficient, and testable recovery strategy through proper disaster recovery planning, while addressing the growing challenge of IBM i skills availability through proper documentation, automation, and partnerships with experienced disaster recovery vendors.
Frequently Asked Questions (FAQ)
How do I handle commitment control boundaries during IBM i disaster recovery testing?
Commitment control requires special attention in DR scenarios. Ensure your it disaster recovery solutions support commitment control boundaries, configure apply processes to respect transaction boundaries (never partial commits), and monitor for long-running transactions that can delay replication. During failover, verify that all commitment control transactions are either fully committed or rolled back. Consider system value settings for automatic thread handling.
What are the best practices for managing Save Files (SAVF) in backup disaster recovery environments?
Save files require different handling than journaled objects—a key consideration for disaster recovery companies. Replicate save files using object replication (not journaling), monitor QGPL and other libraries for temporary save files that shouldn’t replicate, establish clear naming conventions, and regularly clean up obsolete save files to reduce replication overhead. Consider using dedicated libraries for DR-relevant save files.
How do I ensure third-party IBM i applications work correctly after failover with disaster recovery vendors?
Third-party applications often have dependencies requiring attention during disaster recovery testing services. Document all license keys and activation codes (may be processor-specific), test application-specific subsystems and job descriptions, verify exit programs and trigger programs are properly registered, check for hardcoded IP addresses or system names, and ensure vendor support agreements cover DR system access. Maintain detailed documentation of any custom modifications.
What’s the recommended approach for disaster recovery testing without impacting production?
Isolated testing requires careful disaster recovery planning. Use restricted state or dedicated test LPARs, implement network isolation through VLANs, create test library lists that don’t reference production, use journaling or commitment control for test transaction rollback, and employ technologies like FlashCopy for point-in-time testing environments. Always verify complete isolation from production systems when working with managed disaster recovery configurations.
How do I handle IBM i PTF application in a replicated environment following disaster recovery best practices?
PTF management in DR requires coordination that experienced disaster recovery vendors understand. Apply PTFs first to DR system during maintenance windows, test thoroughly before production application, use PTF groups (MF992xx for 7.3, MF993xx for 7.4, MF994xx for 7.5) to ensure consistency, document any PTF-related replication issues, and maintain a PTF regression plan for both systems. Consider using image catalogs for consistent deployment and always verify replication software compatibility with new PTF levels.
